With Machine Learning, Predictive Modeling for Admissions Is Evolving
by JC Bonilla · Updated Apr 27, 2021
In 1992, Ronald F. Urban, director of institutional research at Whitman College, proposed an innovative approach to increase admission yields.
Urban described how political campaigns identify precincts with swing voters receptive to their candidate and those mostly populated with voters set on other candidates. They then allocate resources towards the areas with more swing voters.
Urban said that admissions offices should adopt a similar strategy for recruiting students. He provided a predictive equation for determining students more likely to enroll in one school over another. This launched the predictive modeling techniques colleges and universities use today.
A lot has changed since Urban’s original proposal. New technologies, better and more varied sources of data, as well as machine learning, have opened the door for even greater insights for the admissions professional. And while intuition, admissions knowledge, and being a great communicator will always be your best guides, using data analytics and predictive modeling can give you a powerful competitive advantage.
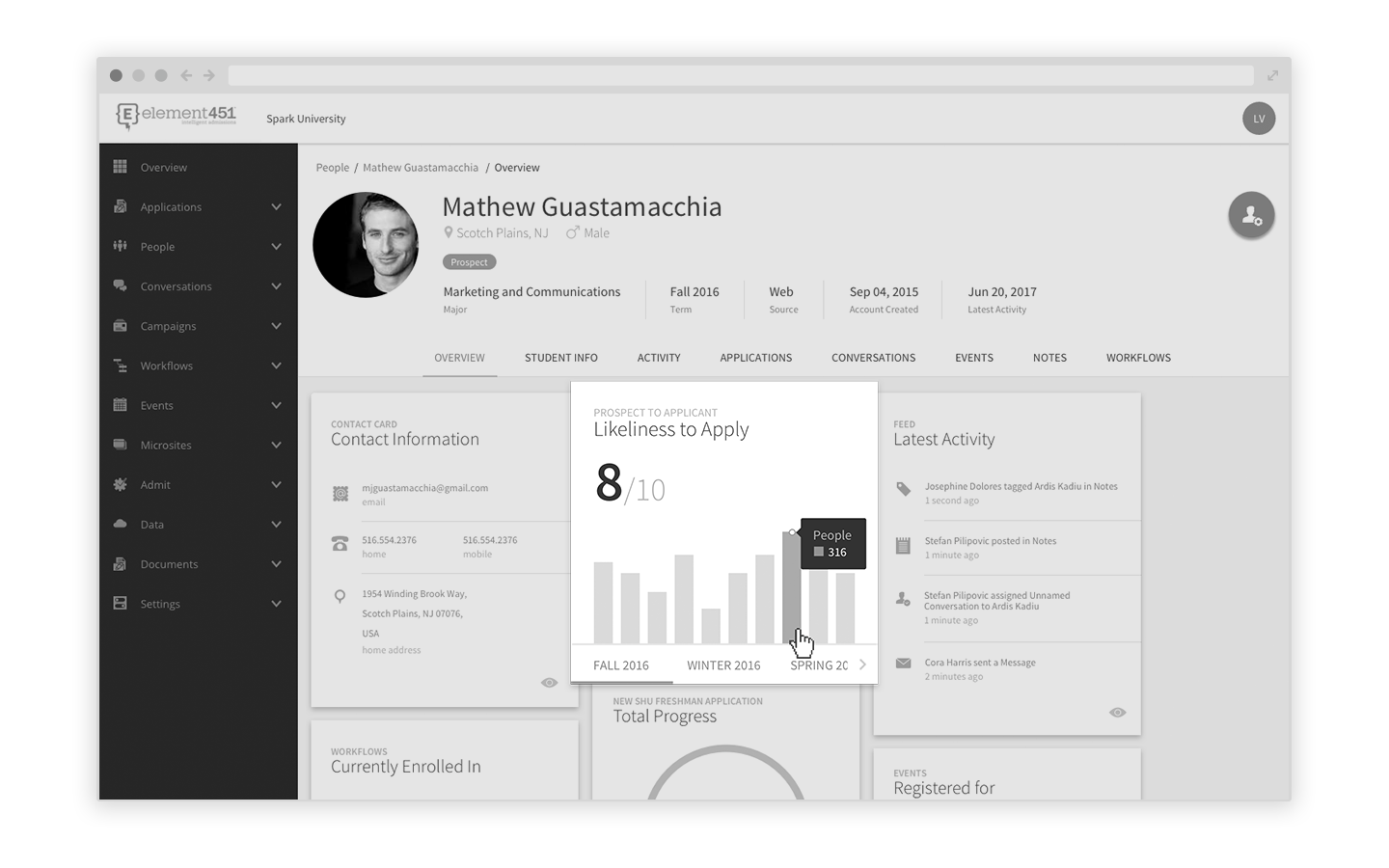
Fit Scoring
Predictive modeling shows schools who among their prospects (from purchased lists and other sources) have the highest probability of choosing their school. With this insight, schools target activities and resources towards prospects who will be most interested in them. It’s about using resources as efficiently as possible. For example, let’s say you have 24,000 prospects who are rising seniors, and your budget will only allow you to mail 10,000 of your fancy — and expensive — new viewbooks. How do you determine which of those prospects should receive a viewbook?
Predictive models start by looking at characteristics of current and graduated students and applicants. Characteristics, or features, include things like high school GPA, SAT and ACT scores, academic interests, financial need, geographic location, ethnicity, and extracurricular activities. Software compares that data to data about the same characteristics for prospects. The desired outcome, applying or enrolling (y), is modeled as a function of the various characteristics (x). You may recall using a simplified version of this equation in high school mathematics: y=f(x)
When prospect data is incomplete, it’s possible to enrich the data with other sources. This is something Element451 often does for our clients.
The final step is generating a score that indicates how likely it is that a prospect will apply and enroll. The score represents the “fit” of the prospect to past applicants and enrollees.
Schools successfully use fit scores to prioritize admissions dollars and energy. They also use predictive modeling to shape classes. Take for example, schools that want to diversify their student body. They can adjust the model to segment groups who are underrepresented in their current classes and find prospects that fit those features.
While fit scores serve admissions teams well, until recently there has been a missing piece of the prospect profile: behavior.

Behavior Scoring
Behavior refers to the ways prospects interact with a school’s communications, its website, or even competing schools’ sites. Examples that Element451 looks at include filling out a request for information form, clicking a link in an email, starting an application, unsubscribing from text messages, and web browsing habits.
Added up, these behaviors provide a much richer understanding of how likely a prospect is to enroll than fit alone. Behavior information can also substitute fit data when historical records aren’t available.
How is behavior captured and analyzed? Element451's integrated modules cover every stage of the admissions process. Campaigns451, for example, is for email and SMS marketing. App451 is for building and managing online applications.
As prospects interact with the various communications and web properties that a school creates with Element451, as well as pixels on their own websites, their behaviors feed into the platform’s database. We are developing the capability to analyze this data instantly. This will give clients predictive scores that update every hour rather than at the start of an admissions cycle.
With machine learning, we’re able to continuously improve our models by adjusting the influence of behavior variables to match their significance. This will result in more accurate scores and insights on how to better craft messages and communications, and even when and how to deliver them.
Stealth No More
Admissions professionals are contending with an increase in “stealth applicants” — students who apply to a school but aren’t part of the prospect pool. Because they aren’t known until they apply, it’s difficult to track information that’s useful for future recruiting. When and how did they first interact with the school? Do they enroll more or less than “known” prospects?
In our predictive modeling work, Element451 engineers are expanding the ability to find out who stealth applicants are. We’re using what’s called identity stitching. An example: A stealth student starts an application. They receive an email encouraging them to explore the website. They click the email or click on a link on the application dashboard driving them to the website. That click gives us data we can use to retrospectively stitch the now-known student to anonymous visits they made to the school’s website in the past. We then create a prospect profile for them that identifies their source and helps us better customize content and messaging to their interests.

About Element451
Boost enrollment, improve engagement, and support students with an AI-driven CRM and agent platform built for higher ed. Element451 makes personalization scalable and success repeatable.
Categories
New Blog Posts



The Definitive Guide
AI in Higher Education
Bridge the gap between the latest tech advancements and your institution's success.
Useful Links

Talk With Us
Element451 is an AI-driven CRM and AI agent platform for higher education. Our friendly experts are here to help you explore how Element451 can improve outcomes for your school and students.
Get a Demo

